Introducing Elixir

엘릭서 프로그래밍 언어를 만든 호세 발림은 한때 루비 히어로에 선정될 만큼 열성적으로 활동하던 레일즈 코어 팀 멤버였습니다. 루비 성능과 동시성 문제를 개선하기 위해 고민하던 차에 터널 증후군이 찾아와 오랜 기간 키보드를 잡을 수 없었고, 그동안 할 수 있는 것이라곤 여러 논문과 자료를 살펴보는 것뿐이었습니다. 그러던 중 그는 유선전화 시대 동시성과 고가용성을 지향했던 얼랭에 푹 빠져들게 되었고, 이후 얼랭의 동시성 기반 위에 훌륭한 개발 도구, 높은 생산성과 코딩의 즐거움으로 유명했던 루비 언어의 장점을 얹은 엘릭서 프로그래밍 언어를 개발하게 되었습니다.
얼랭의 설계 방향은 최근 멀티 코어, 분산, 실시간이 강조된 현대 애플리케이션의 요구사항과 맞아 떨어졌기 때문에 재조명되고 있고, 얼랭 기반의 엘릭서와 엘릭서를 기반으로 하는 웹 프레임워크인 Phoenix 는 개발자들로부터 상당히 긍정적인 평가를 받고 있습니다.
StackOverflow Survey 2022 에서 긍정/부정 비율 순위를 확인해보겠습니다.
Loved vs Dreaded Programming, scripting, and markup languages
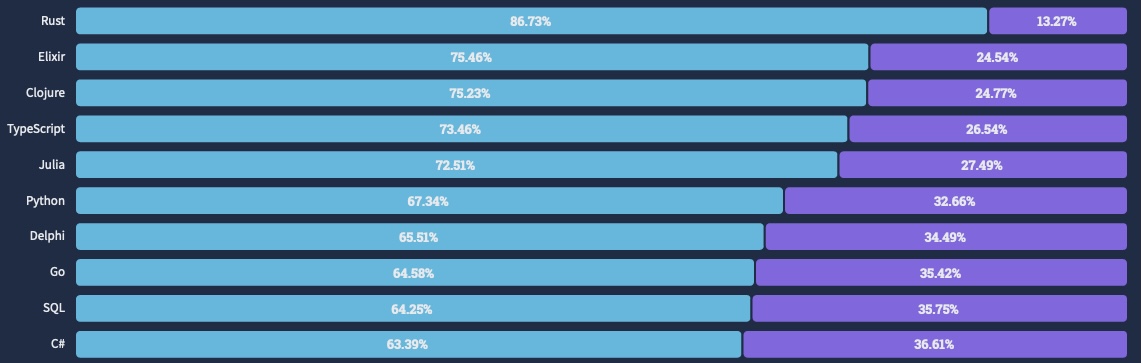
Loved vs Dreaded Web frameworks and technologies

엘릭서의 어떤 점들이 이처럼 개발자들에게서 긍정적인 평가를 받게 되었을까요?
엘릭서 언어는 다음과 같은 특징들을 가지고 있으며, 이에 대해 하나씩 살펴보도록 하겠습니다.
- 코드 생산성
- 함수형 언어
- 확장성
- 안정성
- 간단하면서도 강력한 모듈, 함수 구조
- 보안 및 안전
- 에코 시스템
- 인터랙티브 개발 환경
코드 생산성
엘릭서는 다른 언어와 비교했을 때, 상대적으로 적은 양의 코드로 동일한 기능을 구현할 수 있습니다. 실제로 사용자들에게 사랑받는 상위 랭킹에 있는 대부분의 언어들(Rust, Elixir, Clojure, Julia)은 다른 언어들과 비교했을때 상대적으로 적은 양의 코드로 동일한 기능을 구현할 수 있게 해 줍니다.
루비 언어는 이와 같은 이유로 인해 많은 인기를 얻었지만, 이에 대한 댓가로 성능과 확장성을 희생했습니다.
엘릭서의 중요한 목표중의 하나는 코드베이스를 과도하게 복잡하게 만들지 않도록 하는 구조를 만듦으로써 사용 용이성과 유지보수를 쉽게 할 수 있게 하는 것입니다.
함수형 언어
엘릭서는 함수형 프로그래밍 언어이며, 언어 자체에서 불변성을 지원합니다.
불변 데이터
엘릭서에서는 모든 값이 불변입니다. DB 레코드와 같은 복잡한 중첩된 리스트 데이터까지도 모두 불변입니다.
불변 데이터를 사용하는 접근 방식이 비효율적이라고 생각하기 쉽습니다. 갱신이 일어날 때마다 데이터 복사본을 새로 만들어내고, 이전에 생성된 많은 값들을 가비지 컬렉션해야 하기 때문입니다.
데이터 복사
일반적으로 모든 데이터 복사는 비효율적이라고 여겨지지만, 사실은 이미 존재하는 데이터가 불변이므로, 새로운 자료구조를 만들 때도 이전에 존재하는 데이터의 일부 또는 전부를 재사용할 수 있습니다.
예를 들어, [head | tail] 라는 연산자는 첫 번째 요소가 head이고, 나머지 요소가 tail인 새로운 리스트를 생성합니다.
list1 = [3, 2, 1]
list2 = [4 | list1]대부분의 언어는 4, 3, 2, 1 을 값으로 가지는 list2를 새로 생성하면서, list1에 있는 값 세 개가 list2의 끝에 복사됩니다. list1이 가변 데이터일 수 있으므로 일반적으로는 이렇게 처리하는게 맞습니다.
하지만 엘릭서에서는 list1이 변하지 않으므로 4를 첫 번째 요소로 하고 그 뒤에 list1의 참조를 그대로 붙여 간단히 새 리스트를 생성합니다.
가비지 컬렉션
데이터를 변형하는 언어의 또 다른 성능 문제는, 이전 값에서 새 값을 만들 때마다 사용하지 않는 값들이 계속 힙heap 메모리를 많이 차지하므로 가비지 컬렉터가 오래된 값들을 정리해주어야 한다. 이 과정에서 모든 작동을 중단하는 stop the world! 가 발생하게 되고, 서버를 운영하는 입장에서는 성능에 부정적인 영향을 미치게 됩니다.
하지만 엘릭서는 아주 많은 프로세스를 사용하는 코드를 작성할 수 있습니다. 각 프로세스는 각자의 힙을 가지게 되고, 애플리케이션의 데이터가 여러 프로세스로 분산되므로 각각의 힙은 모든 데이터가 하나의 힙에 포함될 때보다 훨씬 작습니다. 결과적으로 가비지 컬렉션이 더 빠르게 수행되며, 만일 힙이 가득 차기 전에 프로세스가 종료되면 모든 데이터가 사라지므로, 가비지 컬렉션을 하지 않아도 원하는 효과를 얻을 수 있습니다.
파이프라인
유닉스 사용자라면 유닉스 철학을 경험적으로 알고 있습니다.
- 각 프로그램이 하나의 일을 잘 할 수 있게 만들 것. 새로운 일을 하려면, 새로운 기능들을 추가하기 위해 오래된 프로그램을 복잡하게 만들지 말고 새로 만들 것.
- 모든 프로그램 출력이 아직 잘 알려지지 않은 프로그램이라고 할지라도 다른 프로그램에 대한 입력이 될 수 있게 할 것. 무관한 정보로 출력을 채우지 말 것. 까다롭게 세로로 구분되거나 바이너리로 된 입력 형식은 피할 것. 대화식 입력을 고집하지 말 것.
- 소프트웨어를 설계하고 구축할 때 빠르게 써볼 수 있게 할 것. 심지어 운영체제라도 이상적으로는 수 주 내로. 어설픈 부분을 버리고 다시 만드는 것을 주저하지 말 것.
- 프로그래밍 작업을 가볍게 하기 위해, 심지어 우회하는 방법으로 도구를 만들고 바로 버릴지라도 어설픈 도움 보다는 도구 사용을 선호할 것.
각각의 작은 프로그램은 자신이 해야 할 일 한가지만 잘하면 되고, 이렇게 하면 테스트하기도 쉬워집니다. 또한 명령어 파이프라인이 병렬적으로 실행됩니다.
$ grep elixir *.pml | wc -l단어 수를 세는 wc는 grep와 동시에 실행된다. grep의 출력이 만들어지는 즉시 wc에서 사용되기 때문에, grep이 완료되는 시점과 거의 동시에 최종 결과를 얻을 수 있습니다.
엘릭서에서도 이런 파이프라인을 사용할 수 있습니다.
pmap 이라는 함수는 컬렉션과 함수를 받아, 컬렉션의 각 요소에 함수를 적용한 결과를 리스트로 반환합니다.
단, 각 요소를 변형하는 작업을 별도의 프로세스에서 실행합니다.
여기서는 1,000 개의 백그라운드 프로세스를 만들었고, 머신에 있는 모든 코어와 프로세서를 사용해 실행했습니다.
defmodule Parallel do
def pmap(collection, func) do
collection
|> Enum.map(&(Task.async(fn -> func.(&1) end)))
|> Enum.map(&Task.await/1)
end
end
result = Parallel.pmap 1..1000, &(&1 * &1)파이프 연산자의 좋은 점은 코드를 명세와 닮은 꼴로 쓸 수 있다는 점입니다. 예를 들어 매출-세금을 신고하는 명세서에는 다음과 같이 쓰여 있다고 하겠습니다.
- 고객 명단을 구한다
- 고객들이 주문한 내역을 구한다.
- 주문 내역에 대한 세금을 계산한다.
- 세금을 신고한다.
이 명세를 코드로 바꾸려면 항목 사이에 |>를 넣고 각각을 함수로 구현하기만 하면 됩니다.
DB.find_customers
|> Orders.for_customers
|> sales_tax(2022)
|> prepare_filing함수는 데이터를 변형한다
객체지향 프로그래밍에서는 클래스와 인스턴스를 중심으로 생각하는 데 익숙합니다. 클래스는 행위를 정의하고, 객체는 상태를 저장합니다.
객체를 이용해 코딩하면 상태에 대해 생각하게 됩니다. 객체의 메서드를 호출하고 객체에 다른 객체를 전달하는 일에 개발 시간의 대부분을 사용합니다. 이렇게 메서드가 호출되면 객체는 스스로 상태를 수정하고, 때로는 다른 객체의 상태까지도 수정합니다. 클래스는 각 인스턴스의 동작을 정할 뿐 아니라, 각 인스턴스가 가지고 있는 데이터의 상태까지도 암시적으로 제어합니다. 이렇게 하는 이유는 데이터를 은닉하기 위해서입니다.
하지만 이는 실제 세계와는 동떨어져 있는 경우가 많습니다. 우리는 문제를 해결하고 싶을 뿐이지, 실제 세계에서는 그렇게 많지도 않은 추상적 계층을 굳이 코드로 모델링해서 상태를 관리하고 싶은 건 아닙니다.
예를 들어 보자면, 웹 서버에서는 파일을 다운로드하려는 요청을 파일의 내용을 담은 HTTP 요청으로 변형하게 됩니다. 이 작업은 데이터를 감추고 싶은게 아니라 변형하고 싶을 뿐입니다.
위에서 본 바와 같이 엘릭서는 유닉스 셸과 같은 방식으로 문제를 해결합니다. 명령줄 유틸리티 대신 함수를 사용하는 점이 다를 뿐입니다.
변형transform이라는 개념은 함수형 프로그래밍의 핵심, 즉 ‘함수는 입력을 출력으로 변형한다’라는 사실에 자리 잡고 있습니다.
예를 들어, sin은 pi/4 를 입력하면 0.7071을 출력합니다.
하지만 강력한 기능에는 대가가 따르기 마련입니다. 우리가 그동안 알고 있던 프로그래밍의 거의 전부를 새로 배워야 합니다. 객체 지향 프로그래밍을 하룻밤에 배우지 않았듯, 하루 아침에 함수형 프로그래밍의 전문가가 될 수는 없습니다.
하지만 어느 순간 깨달음이 찾아오게 되면서, 문제를 다른 방식으로 생각하기 시작하고, 아주 작은 수고만으로도 멋진 무언가를 만드는 스스로를 발견할 것입니다.
wc, grep 처럼 여러 용도로 사용할 수 있는 아주 작은 코드 조각을 만들고, 가끔은 예상하지 못한 방법으로 사용하게 될 수도 있습니다.
객체지향 프로그래밍에서 말하던 ‘책임’과 같은 관점에서 생각하기를 그만두고 무언가를 실제로 해결할 방법을 생각한다면 세상을 보는 시각까지도 조금 달라질 수 있습니다. 그리고 대부분 이러한 과정이 꽤 재밌다고 느끼게 될 겁니다.
패턴 매칭
대부분의 언어에서 =는 할당문으로 사용됩니다.
하지만 엘릭서에서는 =는 할당문이 아니라 단언문assertion처럼 동작합니다.
등호 왼쪽을 오른쪽과 같게 만들 방법이 있다면 실행에 성공합니다.
그래서 엘릭서에서는 = 기호를 매치 연산자match operator라고 합니다.
a = 1
# 변수 a에는 이미 1이라는 값을 지정했기 때문에 좌변과 우변이 같으므로 매칭 성공
1 = a
# 실행하려는 코드는 2 = 1 과 같으므로 매칭에 실패해 오류가 발생한다.
2 = a
# 에러 메시지:
# ** (MatchError) no match of right hand side value: 1엘릭서는 좌변을 우변과 같게 만들 방법을 찾는다. 좌변은 변수 세 개를 담은 리스트이고, 우변은 값 세 개로 이루어진 리스트다. 따라서 각 변수마다 위치에 맞는 값을 바인딩하면 양변이 같아진다.
list = [1, 2, 3]
[a, b, c] = list
IO.puts "a=#{a}, b=#{b}, c=#{c}"
# a=1, b=2, c=3이런 과정을 패턴 매칭pattern matching이라 한다.
n! 으로 쓰는 n 팩토리얼은 다음과 같이 정의합니다:
- factorial(0) = 1
- factorial(n) = n * factorial(n-1)
엘릭서 코드에서는 패턴 매칭을 사용해 다음과 같이 팩토리얼을 구현할 수 있습니다.
defmodule Factorial do
def of(0), do: 1
def of(n) when is_integer(n) and n > 0 do
n * of(n-1)
end
end
Factorial.of(10)
# 3628800여기서는 when이라는 가드 조건절을 사용해 조건이 참인 경우에만 함수가 수행되도록 합니다.
음수이거나 정수가 아닌 값을 넣으면 어디에도 매칭되지 않기 때문에 다음과 같은 에러가 발생합니다.
** (FunctionClauseError) no function clause matching in Factorial.of/1참고로 동일한 코드를 타입스크립트로 작성하면 다음과 같습니다:
function factorial(n: number): number {
if (n === 0) {
return 1;
}
if (!Number.isInteger(n) || n < 0) {
throw new Error("invalid input");
}
return n * factorial(n - 1);
}
factorial(10);확장성Scalability
코드를 동시에 독립적으로 실행 가능한 단위로 패키징한다는 개념은 엘릭서의 핵심 기능 중 하나입니다. 전통적인 프로그래밍 언어를 사용해 왔다면 이런 개념이 우려스러울 수 있습니다. 동시성 프로그래밍은 어렵다고 ‘알려져’ 있고, 일반적으로 프로세스를 많이 만들면 성능 면에서 비용이 크기 때문입니다.
얼랭 VM의 구조 덕분에 엘릭서에서는 그런 문제들을 걱정하지 않아도 됩니다. 엘릭서에서는 액터 모델actor model 을 사용합니다. 액터란 다른 프로세스와 데이터를 전혀 공유하지 않는 독립적인 프로세스를 말합니다.
spawn으로 새 프로세스를 생성send로 프로세스에 메시지를 보낸 뒤receive로 돌아오는 메시지를 받는다. 이게 전부입니다. (오류 처리나 모니터링 같은 내용은 나중에 생각하겠습니다.)
엘릭서에서는 다른 언어에서 객체를 만들듯이 새로운 프로세스를 부담없이 생성해 사용합니다.
참고로 엘릭서에서 말하는 프로세스는 무겁고 느린 운영체제 프로세스가 아닙니다. 엘릭서는 얼랭이 제공하는 프로세스를 사용하는데, 얼랭 프로세스는 일반적인 프로세스와 마찬가지로 모든 CPU에서 실행되지만 부하는 매우 적습니다. 일반적인 컴퓨터로도 수만 개의 엘릭서 프로세스를 매우 쉽게 생성할 수 있습니다.
얼랭 프로세스
- 얼랭에서 프로세스는 얼랭 함수를 평가evaluate할 수 있는 작고 독립적인 가상 머신(Virtual Machine)입니다.
- 여러분이 이미 알고 있는 프로세스는 운영체제의 맥락에서이고, 얼랭에서의 프로세스는 운영체제가 아닌 프로그래밍 언어에 속합니다.
- 얼랭 프로세스는 다음과 같은 특성이 있습니다.
- 프로세스 생성과 제거가 매우 빠르다.
- 프로세스 간 메시지 전송이 매우 빠르다.
- 모든 운영체제에서 프로세스가 똑같은 방식으로 동작한다.
- 매우 많은 수의 프로세스를 가질 수 있다.
- 프로세스는 메모리를 공유하지 않으며 완전히 독립적이다.
- 프로세스가 상호작용하는 유일한 방법은 메시지 전달을 통해서다.
- 이러한 이유로 얼랭은 순수 메시지 전달 언어(pure message passing language)로 불립니다.
- 일반적으로 프로세스 프로그래밍은 Memory Violation, 레이스 컨디션, 공유 메모리 손상 등과 같은 문제로 인해 어렵다고 하지만, 얼랭에서는 프로세스 프로그램이 어렵지 않습니다. 기본 명령어인
spawn,send,receive만 있으면 됩니다.
프로세스 간에 메시지를 주고 받는 예제를 살펴보겠습니다.
greet 함수(프로세스)에 문자열을 담은 메시지를 보내면 greet 함수는 받은 메시지를 포함하는 인사말로 응답합니다.
defmodule Server do
def greet do
receive do
{sender, msg} ->
send(sender, {:ok, "Hello, #{msg}"})
end
end
end
# 서버 프로세스 실행
pid = spawn(Server, :greet, [])
# 서버 프로세스로 메시지 전송
send(pid, {self(), "World!"})
# 메시지 받기를 기다린다
receive do
{:ok, message} ->
IO.puts(message)
endspawn함수는 새로운 프로세스를 생성하고 실행하며, 반환값으로는 PID(프로세스 ID)를 반환합니다.send함수는 메시지를 보낼 대상 PID와 보낼 메시지를 전달합니다.receive함수는 받은 메시지를 기다립니다. 매칭하려는 패턴과 그때 실행할 코드를 원하는 만큼 정의할 수 있으며, 처음으로 매칭되는 패턴에 해당하는 코드가 실행됩니다.
spawn 을 사용한 프로세스 생성 시간에 대한 벤치마크 성능을 그래프로 나타내면 다음과 같습니다.
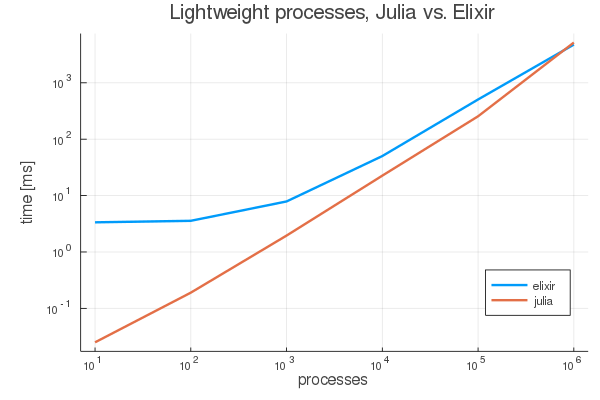
Julia 와 비교한 그래프를 표시했는데, 경량 프로세스 생성 관련해서는 Julia 가 더 좋은 성능을 보여주는 것을 알 수 있습니다. 벤치마크 코드는 이 곳을 참고.
안정성
엘릭서에서는 크래시 발생을 그다지 걱정하지 않습니다. 대신 전체 애플리케이션이 정상적으로 동작하는 것을 중시합니다.
일반적인 애플리케이션은 오류가 제대로 처리되지 않으면 예외가 발생하고 애플리케이션 전체가 멈추게 되며, 재시작되기 전에는 어떤 요청도 수행할 수 없습니다. 서버가 여러 요청을 동시에 처리하는 중이었다면 모든 요청이 유실됩니다. 이러한 구조에서는 단 하나의 오류가 전체 애플리케이션을 멈추게 할 위험이 있습니다.
하지만 애플리케이션이 수천, 수만 프로세스로 구성되고, 각 프로세스가 요청의 아주 작은 부분만을 담당한다고 생각해봅시다. 프로세스 하나에 문제가 생겨 종료되더라도 나머지 프로세스들은 모두 정상적으로 동작합니다. 문제가 생긴 프로세스의 데이터는 유실될 수 있지만, 그 위험마저도 최소가 되도록 애플리케이션을 설계할 수 있습니다. 종료된 프로세스가 다시 재시작되면 애플리케이션은 다시 정상 작동합니다.
엘릭서에서는 이렇게 프로세스를 모니터링하고 재시작하는 모든 작업을 슈퍼바이저supervisor가 담당합니다.
children = [
TCP.Pool,
{TCP.Acceptor, port: 4040}
]
Supervisor.start_link(children, strategy: :one_for_one)슈퍼바이저에는 다음과 같은 관리 전략들이 있습니다:
:one_for_one: 한 서버가 종료되면 슈퍼바이저가 해당 서버만을 재시작.:one_for_all: 한 서버가 종료되면 같은 슈퍼바이저가 관리하는 서버고 모두 종료되고, 종료된 서버가 모두 재시작:rest_for_one: 한 서버가 종료되면 슈퍼바이저의 하위 프로세스 리스트상 종료된 서버보다 뒤에 있는 서버들이 함께 종료되며, 그 뒤 종료된 서버들이 모두 재시작
간단하면서도 강력한 모듈, 함수 구조
엘릭서 언어에는 모듈과 함수라는 두가지 핵심 개념이 있습니다.
전체 애플리케이션은 여러 개의 모듈로 구성되며, 각 모듈은 동일 도메인 기반 함수들의 컨테이너 역할을 합니다. 클래스, 인터페이스, 헤더 파일, 그 외의 보일러 플레이트 코드는 없습니다.
보안 및 안전
엘릭서는 불변 데이터를 사용하며, 이러한 함수형 언어의 특성 덕분에 다음과 같은 이점이 있습니다:
- 예측 가능한 방식으로 코드를 작성하고 테스트할 수 있습니다.
- 디버깅에 많은 시간을 절약할 수 있습니다.
- 사이드 이펙트가 발생하지 않습니다.
피닉스 프레임워크는 레이어가 잘 정의되어 있어 요청 처리 단계를 명확하게 볼 수 있으므로, 원하는 곳을 찾기도 쉽고 안전한 애플리케이션을 만들 수 있습니다.
엘릭서의 사용 사례를 보면, 금용 서비스(예: Klarna)나 대규모 메시징 애플리케이션(예: Discord)에서 사용되고 있습니다. 이러한 대형 상용 애플리케이션에서 문제없이 잘 돌아가고 있다는 것으로 엘릭서와 피닉스의 보안 및 안전성을 확인할 수 있습니다.
에코 시스템
Mix
엘릭서는 Mix 라는 빌드 도구를 제공합니다. Mix 는 다음과 같은 기능을 제공하며, 엘릭서로 작성하기 때문에 커스텀 태스크를 작성하기 쉽습니다.
- 프로젝트 생성
- 컴파일
- 테스트
- 디펜던시 관리
- 얼랭 에코 시스템의 패키지 매니저인 hex를 사용해 디펜던시 관리를 합니다.
자바 생태계의 Gradle 에 해당합니다.
Phoenix
피닉스 개발자 크리스 맥코드는 RubyOnRails(이하 레일즈)로 개발하던 서버 개발자였는데, 레일즈에서 서버기반 상태관리를 하고 싶어서 라이브러리를 만들어가며 연구했지만, 루비와 레일즈에서 제공하는 동시성 수준으로는 한계가 있었고 결국 엘릭서 생태계로 이동해 피닉스를 만들게 되었습니다.
- 피닉스는 레일즈와 유사한 점들이 많으며, 많은 용어와 개념, 명령어들이 레일즈와 대응됩니다.
- 빌트인 Phoenix Channels를 사용해 웹소켓 서버를 구현한 경우, 단일 머신에서 동시에 2백만 유저 이상의 동시 접속을 핸들링할 수 있습니다.
- Phoenix Live View 라는 서버기반 상태관리 기능을 제공합니다.
- 이는 자바스크립트를 사용하지 않고 엘릭서와 피닉스만으로 실시간 서버 렌더링 HTML 을 제공합니다.
- 라이브뷰는 템플릿 기반 HTML 코드를 사용하며, 웹소켓을 통해 클라이언트와 서버가 통신합니다.
- 클라이언트에서 이벤트가 발생하면 이벤트는 서버로 전송되고, 서버는 이벤트를 받아서 서버에 저장된 상태를 기준으로 다시 렌더링하며 diffing 을 통해 변경된 사항만 클라이언트에 전송합니다.
- 클라이언트에서 이벤트 발생시마다 서버에 메시지를 보낸다면 서버에 부하가 걸릴 것이라고 생각할 수 있지만, 엘릭서의 높은 수준의 병렬성을 통해 부하량이 극적으로 줄어드는 장점이 있습니다. 엘릭서 창시자 호세 발림에 의하면 레일즈에서 100개의 서버가 필요했던 환경에서 엘릭서로 이전하고 난 뒤에는 2개의 서버만으로 감당할 수 있었다고 합니다.
- 릴리즈 빌드는 얼랭 VM, Elixir, 디펜던시를 모두 포함하는 단일 패키지를 생성하기 때문에, 사전 설정없이 어느 머신에서도 동작합니다.
인터랙티브 개발 환경
IEx (Elixir’s interactive Shell)
IEx 프롬프트에 엘릭서 코드를 입력하면 결과가 반환되는 인터랙티브 쉘이며 다음과 같은 기능들을 제공합니다.
- 자동 완성
- 디버깅 도구
- 코드 리로딩
- 도움말
$ iex
Interactive Elixir - press Ctrl+C to exit (type h() ENTER for help)
iex> h String.trim # 함수 도움말 출력
iex> i "Hello, World" # 주어진 데이터의 상세한 정보를 출력
iex> break! String.trim/1 # String.trim/1 함수에 브레이크 포인트 설정
iex> recompile # 현재 프로젝트를 다시 컴파일Livebook
브라우저에서 엘릭서 코드를 실행해 차트, 데이터 테이블, 머신 러닝, 문서화와 같은 많은 것들을 지원합니다.
파이썬 생태계의 Jupyter notebook 에 해당합니다.
도커를 사용한 실행 방법:
$ docker run --rm -p 8080:8080 -p 8081:8081 --pull always -u $(id -u):$(id -g) -v $(pwd):/data livebook/livebook참고 문서
- 프로그래밍 얼랭 (조 암스트롱, 인사이트, 2008)
- 처음 배우는 엘릭서 프로그래밍 (데이비드 토머스, 한빛미디어, 2022)
- Why Elixir & Phoenix is a great choice for your web app in 2022
- Elixir homepage
- Phoenix Framework homepage